Utf 16 Character Set Table / UTF-16 - Wikipedia : Emoji sequences have more than one code point in the code column.. The utf‑16 client character set supports utf ‑ 16 encoding. 16 bits is two byte. There are further sql commands to take into account to make sure the data goes in and out in the right format as well. Then teradata add the other columns byte size together to determine the row size used in the bteq/jdbc/odbc/tpt/fexp parcels. Like in morse code dots and dashes represents letters and digits.
For a supplementary character, utf16 has a. 16 bits is two byte. When new characters are added to a code page, the code page number does not change. For example, n'abc' is different in japanese and latin codepages. The size in memory of a string of length n varies based on the particular code points in the string.
How to configure e-mail clients to send UTF-8 text from dotancohen.com For a bmp character, utf16 and ucs2 have identical storage characteristics: Code page 1200 always refers to the current version of unicode. Like in morse code dots and dashes represents letters and digits. Null (u+0000) feff0000 start of heading (u+0001) When new characters are added to a code page, the code page number does not change. The size in memory of a string of length n varies based on the particular code points in the string. They encode differently which alters their usage, but otherwise, they are identical in the characters they provide. Code points with lower numerical values, which tend.
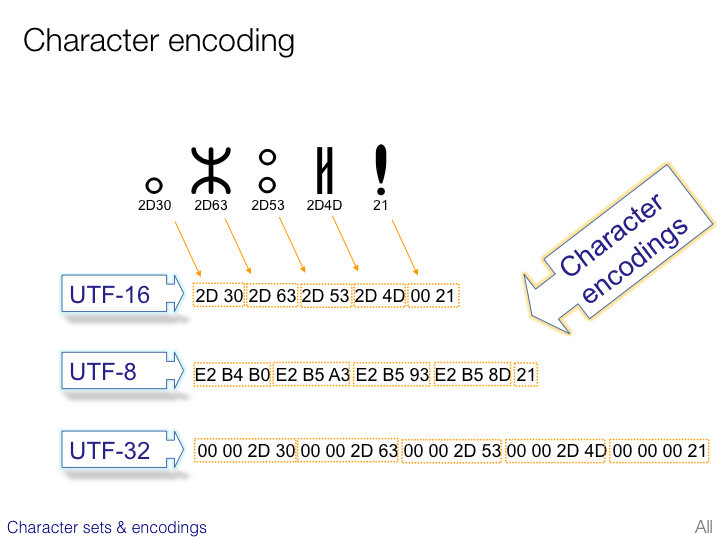
Each character is either 2 or 4 bytes long.
But computer can understand binary code only. Then teradata add the other columns byte size together to determine the row size used in the bteq/jdbc/odbc/tpt/fexp parcels. Even if the row is actually stored on the disk properly within the 64k limit, you still can't retrieve it if the. Instead, specify the layout of the input record. The first 2 bytes that you see are what is known as the byte order mark or bom (which indicates the endianness of the unicode file). While unicode is currently 128,237 characters it can handle up to 1,114,112 characters. The ordering of the emoji and the annotations are based on unicode cldr data. The ascii and ansel character set each have just one encoding. So, encoding is used number 1 or 0 to represent characters. For a bmp character, utf16 and ucs2 have identical storage characteristics: For a supplementary character, utf16 has a. Encoding takes symbol from table, and tells font what should be painted. When new characters are added to a code page, the code page number does not change.
Each character is either 2 or 4 bytes long. Each unit (1 or 0) is calling bit. There are further sql commands to take into account to make sure the data goes in and out in the right format as well. The ascii and ansel character set each have just one encoding. This chart provides a list of the unicode emoji characters and sequences, with images from different vendors, cldr name, date, source, and keywords.
An Introduction to Writing Systems from r12a.github.io Code page 1200 always refers to the current version of unicode. They encode differently which alters their usage, but otherwise, they are identical in the characters they provide. Although unicode administers ascii's original 128 characters, it also updated (but did not replace) a handful of them. Encoding takes symbol from table, and tells font what should be painted. Estimated column size in bytes for varchr (n)/char (n) latin / ascii. For a supplementary character, utf16 has a. There are restrictions imposed by teradata database on using the utf‑8 or utf‑16 character set. There are further sql commands to take into account to make sure the data goes in and out in the right format as well.
Code points with lower numerical values, which tend.
While unicode is currently 128,237 characters it can handle up to 1,114,112 characters. Code page 1200 always refers to the current version of unicode. Character description encoded byte � Most of the characters for all modern languages are represented using 2 bytes. Even if the row is actually stored on the disk properly within the 64k limit, you still can't retrieve it if the. For a bmp character, utf16 and ucs2 have identical storage characteristics: Like in morse code dots and dashes represents letters and digits. Same code values, same encoding, same length. Encoding takes symbol from table, and tells font what should be painted. But computer can understand binary code only. There are restrictions imposed by teradata database on using the utf‑8 or utf‑16 character set. Each character is either 2 or 4 bytes long. When new characters are added to a code page, the code page number does not change.
For example, n'abc' is different in japanese and latin codepages. Character description encoded byte � So, encoding is used number 1 or 0 to represent characters. Circled latin capital letter m: Code page 1200 always refers to the current version of unicode.
Unicode, UTF8 & Character Sets: The Ultimate Guide ... from cloud.netlifyusercontent.com When new characters are added to a code page, the code page number does not change. Most of the characters for all modern languages are represented using 2 bytes. Instead, specify the layout of the input record. Encoding takes symbol from table, and tells font what should be painted. Then teradata add the other columns byte size together to determine the row size used in the bteq/jdbc/odbc/tpt/fexp parcels. The ordering of the emoji and the annotations are based on unicode cldr data. Code page 1200 always refers to the current version of unicode. For example, n'abc' is different in japanese and latin codepages.
Character description encoded byte �
Like in morse code dots and dashes represents letters and digits. For a bmp character, utf16 and ucs2 have identical storage characteristics: There are restrictions imposed by teradata database on using the utf‑8 or utf‑16 character set. Most of the characters for all modern languages are represented using 2 bytes. There are further sql commands to take into account to make sure the data goes in and out in the right format as well. The size in memory of a string of length n varies based on the particular code points in the string. Each unit (1 or 0) is calling bit. Encoding takes symbol from table, and tells font what should be painted. For a supplementary character, utf16 has a. This chart provides a list of the unicode emoji characters and sequences, with images from different vendors, cldr name, date, source, and keywords. The ascii and ansel character set each have just one encoding. Emoji sequences have more than one code point in the code column. Null (u+0000) feff0000 start of heading (u+0001)